
這幾天提到的概念:Feature Crosses、Feature不能太多等等,聽起來是一回事,但做起來又是另外一回事。本篇會稍微玩一下遊戲區,看看這些概念到底在說什麼。
我們使用類似先前範例的四個象限數據,來進行測試。
測試的範圍會是:線性函數的參數X、Y,以及X,Y,最後是Feature太多的話會有怎樣影響。
X和Y的Feature: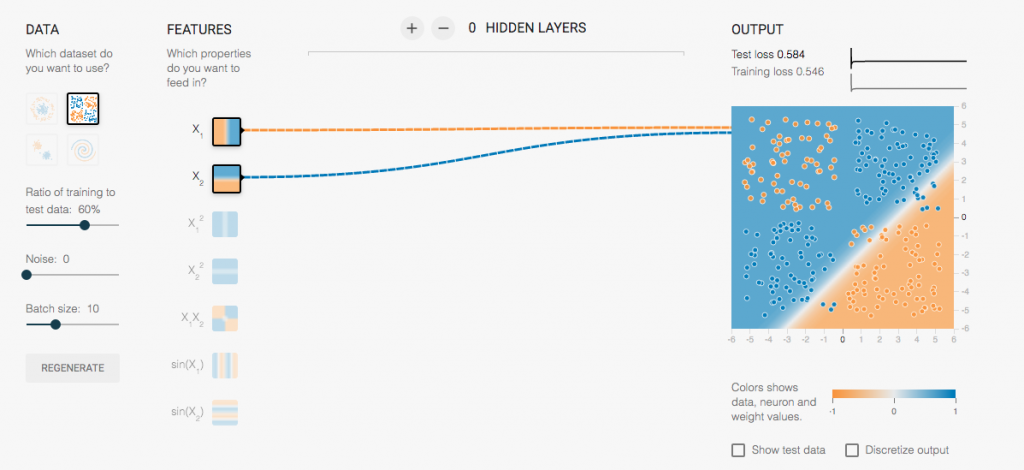
可以看得出來,我們圖的線都是在右下角,但是卻無法把我們的兩種不懂的點點們適當的做區別,所以我們的loss高居不下,達到0.548,完全不能使用這個模型。
X1,Y2的Feature: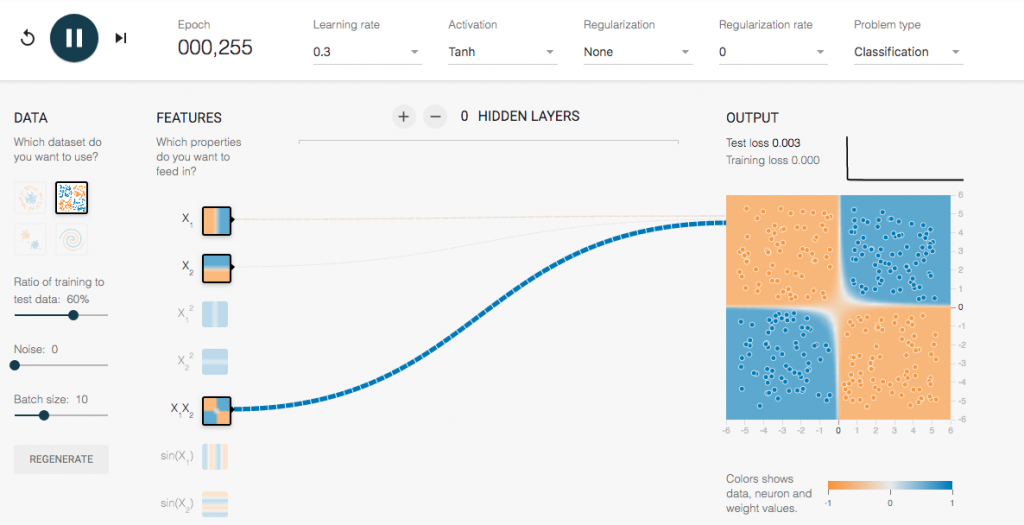
僅使用X1,Y2的方式,可以看得出來很快(實際上不到一百就是現況),就可以把點點們適當分類,並且區分成四塊。而且total loss只有0.003,是個優質的模型。
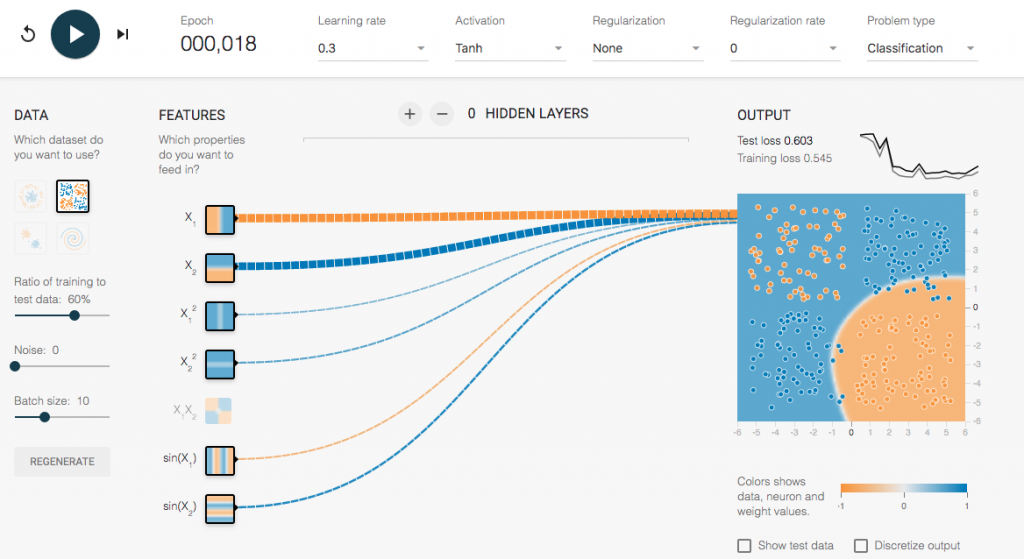
X和Y的Feature。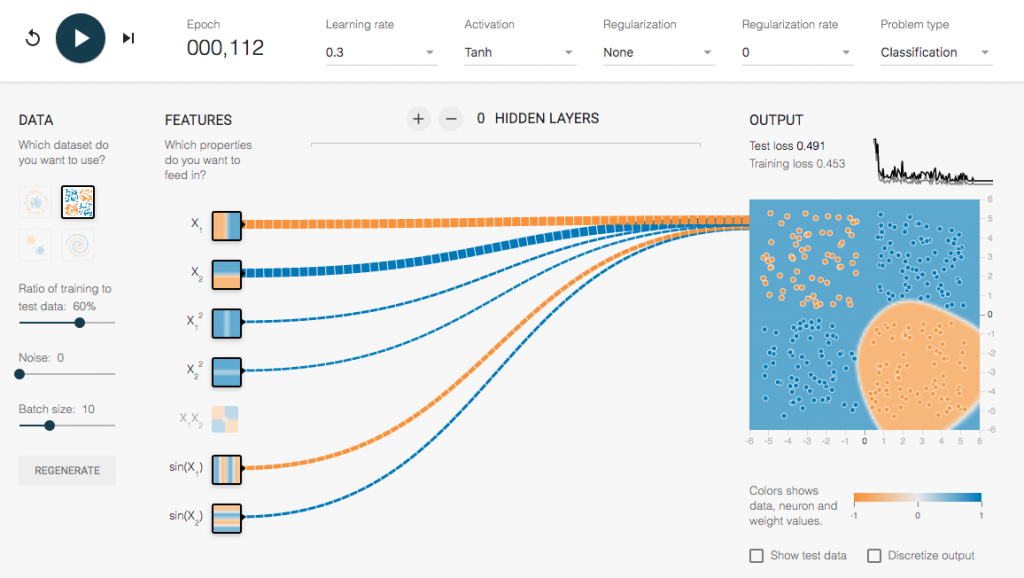
Total loss逐漸縮小,也比較穩定的前進
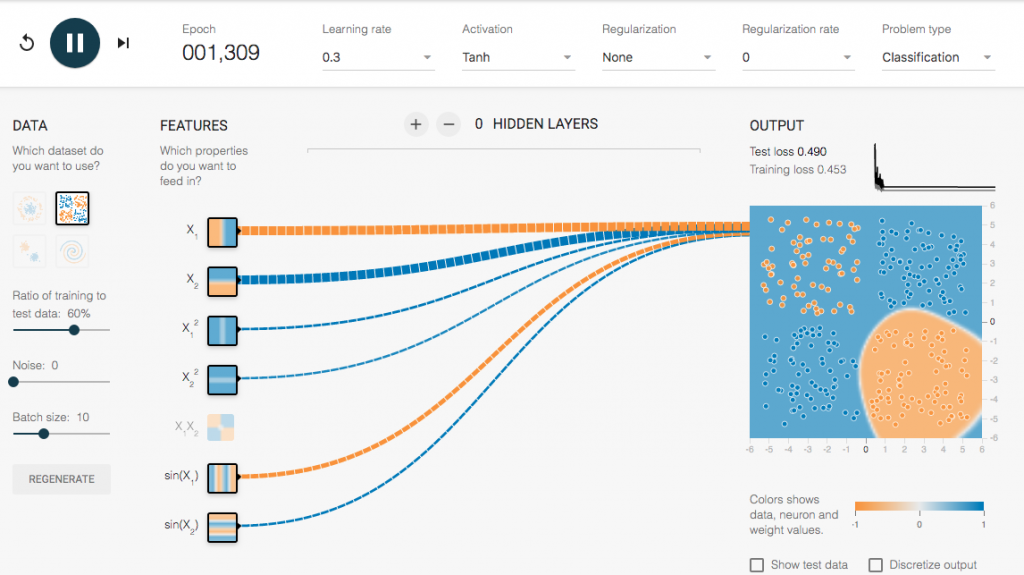
次數多了Total loss也下降了,最後呈現一個穩定值。如果移到最右邊的圖,會發現我們用這些Feature可以區分出,右下角一類,其他同類。但事實上,這個模式也無法完成分出兩個部分。
所以這樣的Feature並不是一個好feature,所以要更換Feature內容。
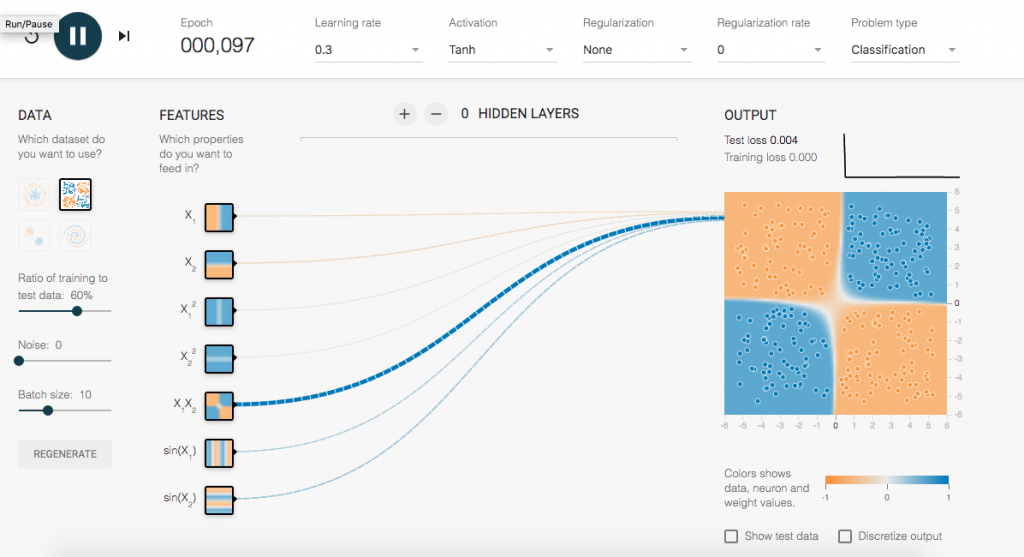
使用兩個參數後,可以看到迅速達到目標,一下子就得到新模型,而且誤差值超低。是個好模型。細看裡面的Feature貢獻粗細,先前的範例都是X和Y,這次X1,Y2獨領風騷,所以這樣才是正解。
但有個更好的方法,更快算出模型: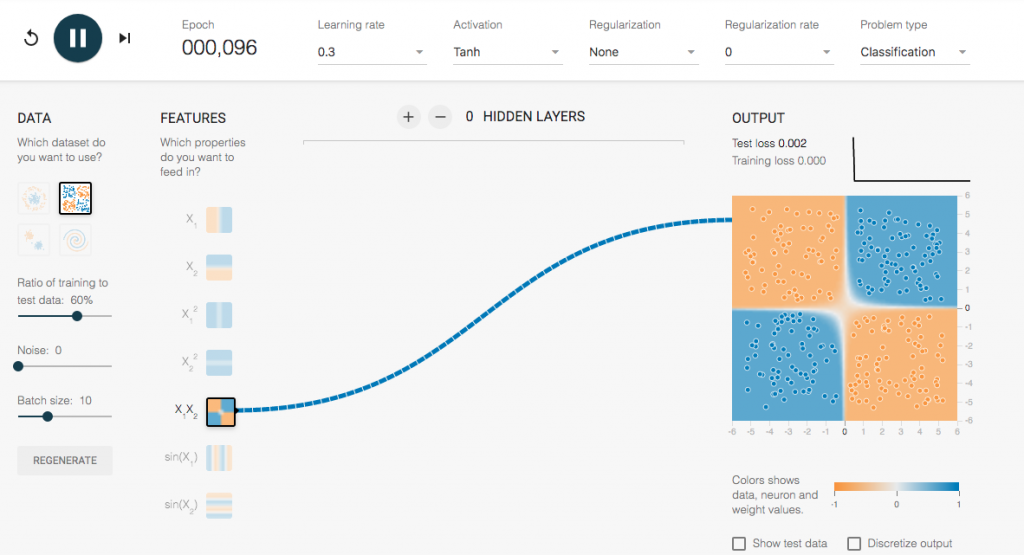
也就是一開始就使用X1,Y2,可以更快速的得到模型,而且提供與整理的資料較少,以比較快完成前置作業。
睫毛之聲:
跟著教學文件說明,再結合playground,讓這幾天抽象的作法與結果,更清楚的表達出來。而這幾天也逐漸看懂playground的各參數意義,更了解目前的作法可以幫助機器學習多少。
真的沒事可以去playground逛逛。
